A Brief Reflection on AutoML
A Brief Reflection on AutoML…
Yesterday I had the great opportunity to participate in the excellent ProdOps channel with Cristiano Milfont and Matheus Duarte to talk about the NLP case in production I worked on at MyHammer where we had a very tight deadline, but in the end, we managed to deliver.
However, the interesting part of our talk was really the discussion about how much AutoML has been taking over the model training part and how practical it is, whether for exhausting a search space in a family of models or even for “saving time” during the execution of other parts of an application in production.
I had already written about AutoML on the Data Hackers blog called “Automated Machine Learning (AutoML): Practical and theoretical aspects, advantages and limitations” and much of what I still think is there.
The example I used during our conversation is that at certain times when we are putting ML algorithms into production, we have to deal with a myriad of things like monitoring, infrastructure, observability, data pipeline, configurations, API development and its endpoints, and so on, and that takes time.
In this case, I used an analogy where if ML development in production were like a restaurant, AutoML would come in as a kind of food processor or a blender that would do part of the repetitive work and bring a uniform and predictable result; while the cooks would worry about the oven, the ingredients in the frying pan, the plating, etc.
And another point that I had already put in the article and that I continue with the same opinion is that data scientists and Machine Learning engineers should spend much less time training models manually and focus on aspects regarding reproducibility, data pipeline, and so on.
And without being afraid to be controversial, the way of training machine learning models in the classical way with manual adjustments, or at most using a questionable grid search, is something that is much less scientific and is much closer to alchemy in methodological terms; more or less like Ali Rahimi’s argument at Neurips 2017 in his talk “Machine learning has become alchemy” where he exposed numerous theoretical problems regarding how even algorithms were being proven in mathematical and formal terms.
This type of training is so methodologically fragile that it still surprises me that data science and Machine Learning education doesn’t address this more seriously; because, while a data scientist does manual fine-tuning or runs a grid search with a set of parameters that are at best cherry-picked; an AutoML algorithm has not only its search space already established but also its convergence path (i.e., how it GOT there) much clearer from a methodological point of view (method here is the means or process of reaching something).
Don’t agree with me? Great, then I’ll refer to this tweet by Erin LeDell from H2O.ai where in just 100 minutes of AutoML she came in eighth place on a public leaderboard in a local Kaggle competition:
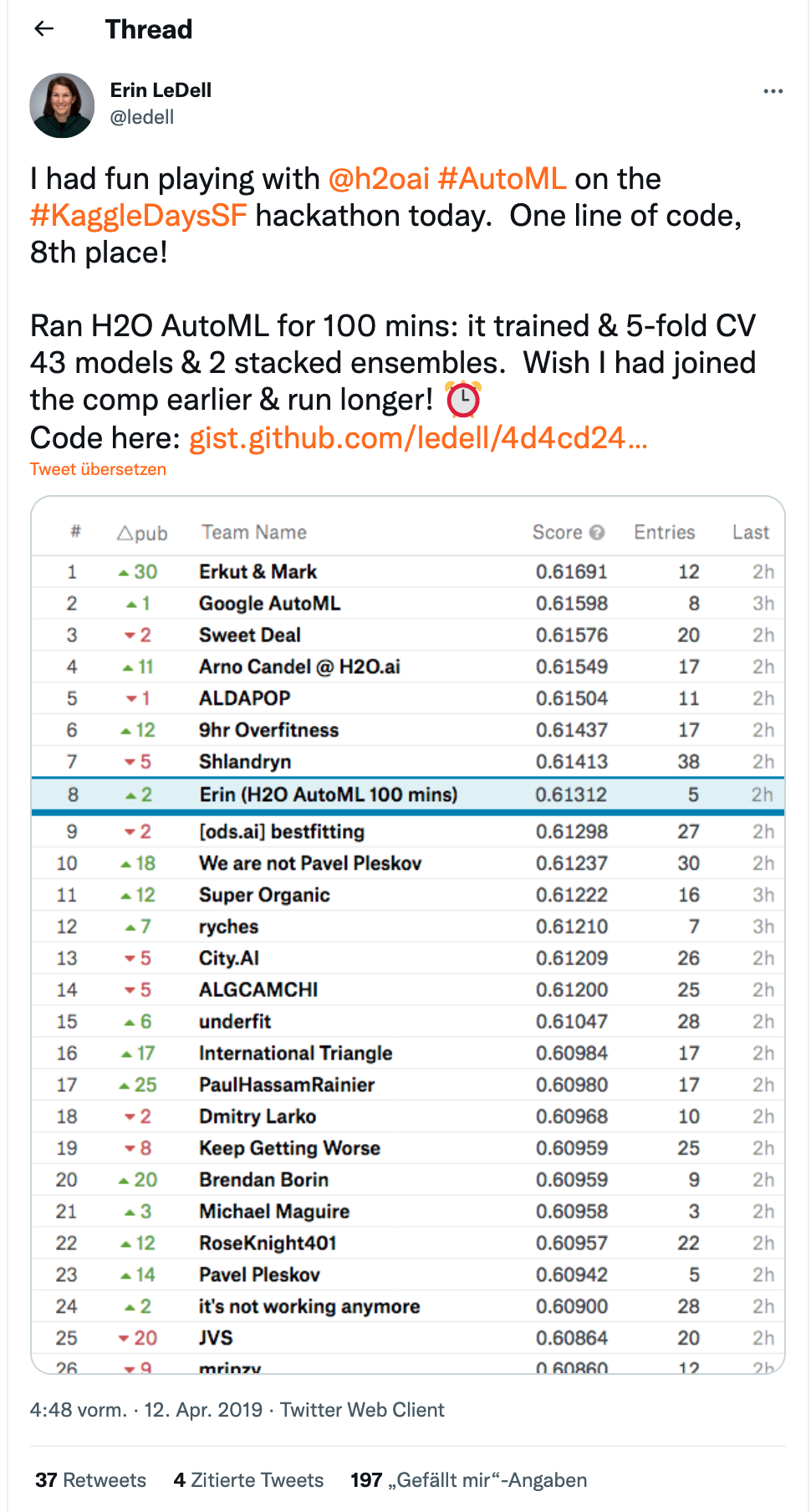
I don’t think it’s the end of the world and I still think that AutoML comes to fill an interesting space for those who need to save time in building models and need to deliver systems, preferably as quickly as possible; but that’s another debate…
For those interested, I made a video for the great Estatidados channel a while ago about AutoML using H2O.ai and R.