Uma breve reflexão sobre o AutoML
Uma breve reflexão sobre o AutoML…
Ontem tive a grata oportunidade de participar o excelente canal do ProdOps com o Cristiano Milfont e Matheus Duarte para falar do case de NLP em produção no qual trabalhei na MyHammer em que tivemos um prazo bem apertado, mas que no final conseguimos entregar.
Contudo a parte interessante do nosso papo foi realmente a discussão sobre o quanto AutoML vem tomando de assalto a parte de treinamento de modelos e o quão prático ele é, seja para exaustão de um espaço de busca em uma familia de modelos ou mesmo para “ganhar tempo” durante a execução de outras partes de uma aplicação em produção.
Eu já tinha escrito sobre o AutoML no blog do Data Hackers chamado “Automated Machine Learning (AutoML): Aspectos práticos, teóricos, vantagens e limitações” e grande parte do que eu ainda penso está lá.
O exemplo em que eu usei durante a nossa conversa é que em determinados momentos quando estamos colocando algoritmos de ML em produção temos que lidar com uma miríade de coisas como monitoramento, infraestrutura, observabilidade, pipeline de dados, configurações, desenvolvimento das APIs e seus endpoints e tudo mais, e isso leva tempo.
Neste caso, eu usei uma analogia em que se o desenvolvimento de ML em produção fosse como um restaurante, o AutoML entraria como uma espécie de processador de alimentos ou um liquidificador que faria uma parte do trabalho repetitivo e que traria um resultado uniforme e previsível; enquanto os cozinheiros iriam se preocupar com o forno, parte dos ingredientes que estão na frigideira, com a montagem do prato, etc.
E um outro ponto que eu já tinha colocado no artigo e que eu continuo com a mesma opinião é que cientistas de dados e engenheiros de Machine Learning deveriam gastar muito menos tempo treinando modelos de forma manual e focar em aspectos em relação a reproducibilidade, pipeline de dados e por aí vai.
E sem ter medo de ser controverso, a forma de treinamento de modelos de machine learning da forma clássica com ajustes manuais, ou no máximo usando um grid search questionável, é algo que é muito menos cientítico e está muito mais perto da alquimia em termos metodológicos; mais ou menos como no argumento do Ali Rahimi na Neurips 2017 em sua palestra “Machine learning has become alchemy” em que ele expos inúmeros problemas teóricos relativos a forma na qual até mesmo os algoritmos estavam sendo provados em termos matemáticos e formais.
Esse tipo de treinamento é tão frágil metodológicamente, que me surpreende ainda que o ensino de ciência de dados e Machine Learning não coloquem isso de uma maneira mais séria; pois, enquanto um cientista de dados faz fine tuning manual ou joga um grid search com um conjunto de parâmetros na melhor das hipóteses cherry-picked; um algoritmo de AutoML tem não somente o seu espaço de busca já estabelecidos como também o seu caminho de convergência (i.e. como ele CHEGOU lá) muito mais claros do ponto de vista metodológico (método aqui é o meio ou o processo de chegar em algo).
Não concorda comigo? Ótimo, então eu vou fazer referência nesse twitt da Erin LeDell da H2O.ai em que ela em apenas 100 minutos de AutoML ficou em oitavo lugar em um leaderboard público em uma competição local do Kaggle:
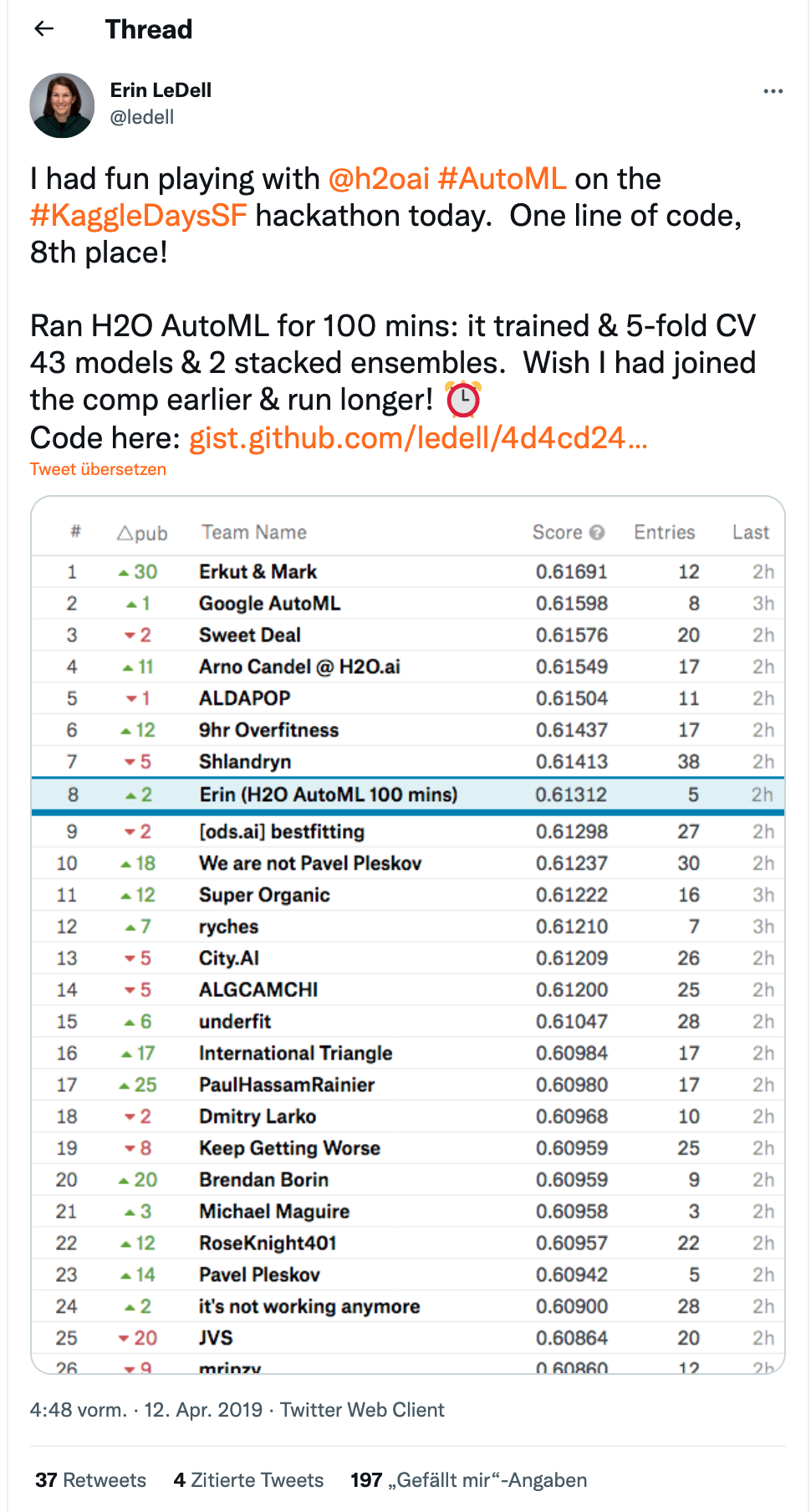
Eu não acho que seja o fim do mundo e ainda penso que o AutoML vem para preencher um espaço interessante para quem precisa ganhar tempo na construção de modelos e precisa entregar sistema, de preferência o mais rápido possível; mas isso é outro debate…
Para quem estiver interessado, eu fiz um vídeo para o ótimo canal do Estatidados a algum tempo sobre AutoML usando o H2O.ai e o R.