Ou isso vai acontecer...
Ou isso vai acontecer…
O John Cutler que provavelmente produz um dos melhores conteúdos de produto no Twitter fez um gráfico que simplesmente sumariza muito dos times de Machine Learning, Ciência de Dados e Engenharia de Dados que eu vejo nas comunidades e no mercado em geral aqui na Europa e no Brasil.
Em suma esse é o twitt:
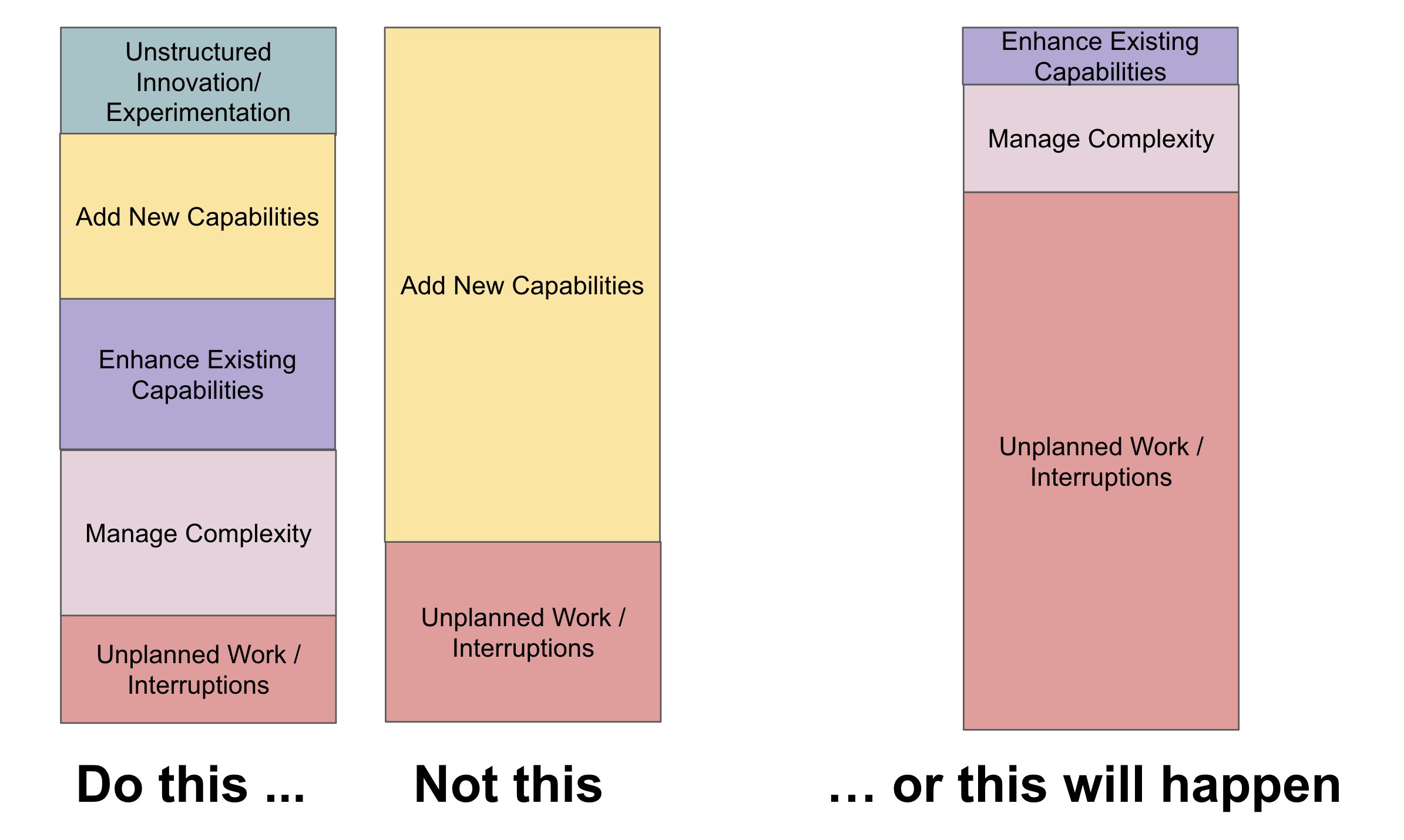
Tomando a liberdade de expandir o raciocínio para times de Machine Learning, seria algo mais ou menos assim pela minha experiência:
Faça isso:
- Inove de maneira não estruturada/Experimentação (Via pequenos e incrementais ajustes em algoritmos e melhor engenharia de features; se possível testando frameworks de mercado)
- Adicione novas capacidades (através de treinamentos em operações de machine learning, deployment ambientes em cloud, fundamentos de engenharia de software, SOLID, conhecimentos sobre REST API)
- Melhore capacidades existentes (conhecimento a fundo dos modelos em produção, otimizações de desempenho em APIs existentes, melhoria da base estatística para a produção de melhores EDAs)
- Gerencie complexidade (em relação ao drift de dados e modelos, mudanças nas distribuições dos dados de treinamentos, entendimento básico de causalidade e a sua influência nos dados)
- Lide com trabalho não planejado/interrupções (retreinamento de modelos que não performam bem em produção, ausência de reprodutibilidade, pipeline jungles, glue code)
Ao invés de:
- Adicione novas capacidades (através de treinamentos em operações de machine learning, deployment ambientes em cloud, fundamentos de engenharia de software, SOLID, conhecimentos sobre REST API)
- Lide com trabalho não planejado/interrupções (retreinamento de modelos que não performam bem em produção, ausência de reprodutibilidade, pipeline jungles, glue code)
… ou isso vai acontecer:
- Melhore capacidades existentes (conhecimento a fundo dos modelos em produção, otimizações de desempenho em APIs existentes, melhoria da base estatística para a produção de melhores EDAs)
- Gerencie complexidade (em relação ao drift de dados e modelos, mudanças nas distribuições dos dados de treinamentos, entendimento básico de causalidade e a sua influência nos dados)
- Lide com trabalho não planejado/interrupções (retreinamento de modelos que não performam bem em produção, ausência de reprodutibilidade, pipeline jungles, glue code)
…
Dentro do que eu já vivenciei em alguns times, o pior trabalho não planejado não é aquele devido a débito técnico conhecido e aceito, mas sim problemas que ocorrem por conta de ausência de capacidades (skill gap) e relativo ao mau gerenciamento de complexidade seja ela acidental ou não.