14 · DECEMBER · 2021
Or This Will Happen...
Or This Will Happen…
John Cutler, who probably produces some of the best product content on Twitter, made a chart that simply summarizes many of the Machine Learning, Data Science, and Data Engineering teams I see in communities and the market in general here in Europe and Brazil.
In short, this is the tweet:
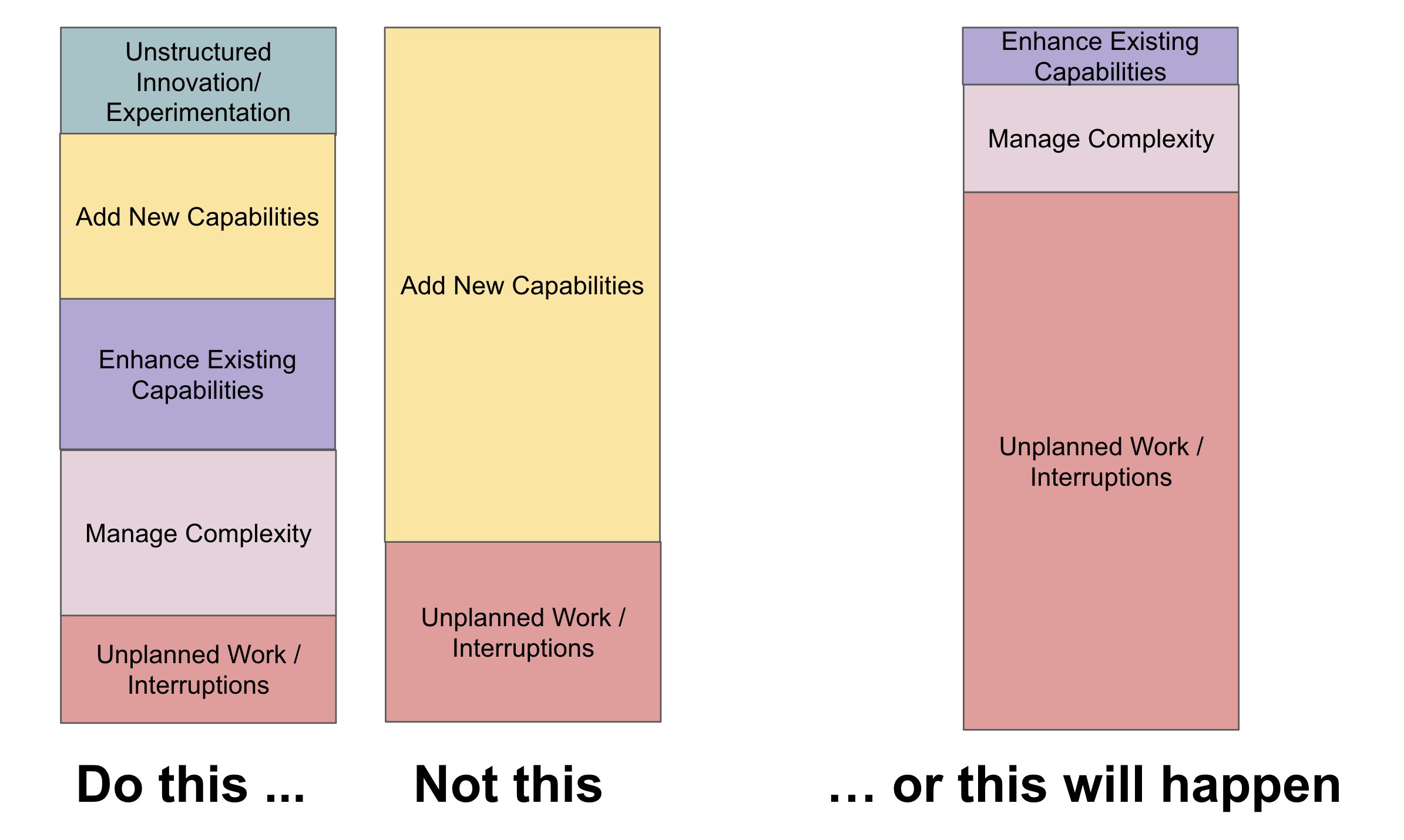
Taking the liberty to expand the reasoning for Machine Learning teams, it would be something like this based on my experience:
Do this:
- Innovate in an unstructured way/Experimentation (Via small and incremental adjustments in algorithms and better feature engineering; if possible, testing market frameworks)
- Add new capabilities (through training in machine learning operations, cloud environment deployment, software engineering fundamentals, SOLID, knowledge about REST API)
- Improve existing capabilities (in-depth knowledge of production models, performance optimizations in existing APIs, improving the statistical base for producing better EDAs)
- Manage complexity (regarding data and model drift, changes in training data distributions, basic understanding of causality and its influence on data)
- Handle unplanned work/interruptions (retraining of models that don’t perform well in production, lack of reproducibility, pipeline jungles, glue code)
Instead of:
- Add new capabilities (through training in machine learning operations, cloud environment deployment, software engineering fundamentals, SOLID, knowledge about REST API)
- Handle unplanned work/interruptions (retraining of models that don’t perform well in production, lack of reproducibility, pipeline jungles, glue code)
… or this will happen:
- Improve existing capabilities (in-depth knowledge of production models, performance optimizations in existing APIs, improving the statistical base for producing better EDAs)
- Manage complexity (regarding data and model drift, changes in training data distributions, basic understanding of causality and its influence on data)
- Handle unplanned work/interruptions (retraining of models that don’t perform well in production, lack of reproducibility, pipeline jungles, glue code)
…
From what I’ve experienced in some teams, the worst unplanned work is not that due to known and accepted technical debt, but rather problems that occur due to a lack of capabilities (skill gap) and related to poor management of complexity, whether accidental or not.