Paper bem atual que fala como os autores erraram a crise apenas em relação ao ano mostrando o potencial das Random Forests. 
Predicting Economic Recessions Using Machine Learning Algorithms - Rickard Nyman and Paul Ormerod
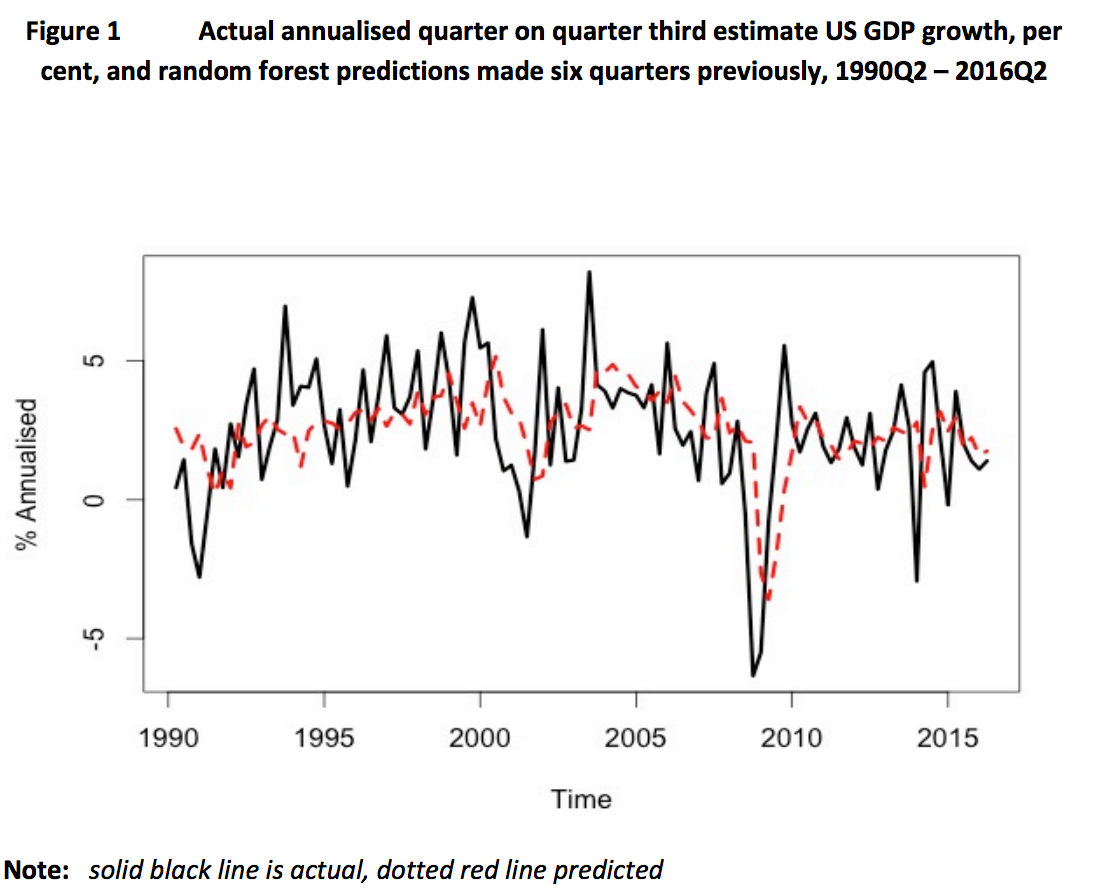
Abstract Even at the beginning of 2008, the economic recession of 2008/09 was not being predicted by the economic forecasting community. The failure to predict recessions is a persistent theme in economic forecasting. The Survey of Professional Forecasters (SPF) provides data on predictions made for the growth of total output, GDP, in the United States for one, two, three and four quarters ahead, going back to the end of the 1960s. Over a three quarters ahead horizon, the mean prediction made for GDP growth has never been negative over this period. The correlation between the mean SPF three quarters ahead forecast and the data is very low, and over the most recent 25 years is not significantly different from zero. Here, we show that the machine learning technique of random forests has the potential to give early warning of recessions. We use a small set of explanatory variables from financial markets which would have been available to a forecaster at the time of making the forecast. We train the algorithm over the 1970Q2-1990Q1 period, and make predictions one, three and six quarters ahead. We then re-train over 1970Q2-1990Q2 and make a further set of predictions, and so on. We did not attempt any optimisation of predictions, using only the default input parameters to the algorithm we downloaded in the package R. We compare the predictions made from 1990 to the present with the actual data. One quarter ahead, the algorithm is not able to improve on the SPF predictions. Three and six quarters ahead, the correlations between actual and predicted are low, but they are very significantly different from zero. Although the timing is slightly wrong, a serious downturn in the first half of 2009 could have been predicted six quarters ahead in late 2007. The algorithm never predicts a recession when one did not occur. We obtain even stronger results with random forest machine learning techniques in the case of the United Kingdom.
Conclusions: We have tried, as far as it is possible, to replicate an actual forecasting situation starting for the United States in 1990Q2 and moving forward a quarter at a time through to 2016. We use a small number of lags on a small number of financial variables in order to make predictions. In terms of one step ahead predictions of real GDP growth, we have not been able to improve upon the mean forecasts made by the Society of Professional Forecasters. However, even just three quarters ahead, the SPF track record is very poor. A regression of actual GDP growth on the mean prediction made three quarters previously has zero explanatory power, and the SPF predictions never indicated a single quarter of negative growth. The random forest approach improves very considerably on this. Even more strikingly, over a six period ahead horizon, the random forest approach would have predicted, during the winter of 2007/08, a severe recession in the United States during 2009, ending in 2009Q4. Again to emphasise, we have not attempted in any way to optimise these results in an ex post manner. We use only the default values of the input parameters into the machine learning algorithm, and use only a small number of explanatory variables. We obtain qualitatively similar results for the UK, though the predictive power of the random forest algorithm is even better than it is for the United States. As Ormerod and Mounfield (2000) show, using modern signal processing techniques, the time series GDP growth data is dominated by noise rather than by signal. So there is almost certainly a quite restrictive upper bound on the degree of accuracy of prediction which can be achieved. However, machine learning techniques do seem to have considerable promise in extending useful forecasting horizons and providing better information to policy makers over such horizons.